Not registered? - Request an account here

RASM2018 Resources
Access to Datasets
Please email us at rasm2018@primaresearch.org to get access to the competition datasets (example set with ground truth and evaluation set images).
Overview
Provided to participants:
- Example images with ground truth (in PAGE XML format)
- Software libraries and tools to create/view PAGE and to run OCR
- Support
To be delivered by participants:
- Page segmentation / region classification, text line segmentation, and OCR results in valid PAGE XML (see examples below )
- Access to the executables/systems of the candidate methods
- A short description of the method (250 words)
Ground Truth Format
The ground truth for each image is provided in the PAGE (Page Analysis and Ground truth Elements) format. For a description of the relevant parts (for this competition) of the XML file structure please see the section "Page analysis and recognition results" below.
PAGE has been developed on a long working experience in creating, managing and using datasets, including the PRImA Layout Analysis Dataset and the large and significant historical document dataset of the EU-funded IMPACT project.
More details on the PAGE format can be found in the following paper:
S. Pletschacher, A. Antonacopoulos, "The PAGE (Page Analysis and Ground-Truth Elements) Format Framework", Proceedings of the 20th International Conference on Pattern Recognition (ICPR2010), Istanbul, Turkey, August 23-26, 2010, IEEE-CS Press, pp. 257-260. [further details]
And in the actual XML Schema:
http://schema.primaresearch.org/PAGE/gts/pagecontent/2017-07-15/pagecontent.xsd
The format provides for the representation of several different region types, which may be subject to different processing in recognition systems. The most important types of region for challenge 1 are text paragraphs, text marginalia, and graphics / line drawings.
For each region there is a description of its outline in the form of a closely fitting polygon. Such a representation enables a very accurate and efficient geometric description, especially for complex-shaped regions. Text regions may also contain Unicode text content.
A simple example XML is described in this document
Submission requirements
Authors of methods should submit the following by e-mail to the organisers:
- Page analysis and recognition results in PAGE format (see below)
- Access to the executables/systems of the candidate methods
- A short description (250 words) of the methods (principles of operation and steps). Cite and attach any relevant publications, if available.
Page analysis and recognition results
The results must be stored in the PAGE format (same format as the ground-truth provided). Evaluation will be based on detected regions (location, type and subtype), detected text lines (location) and detected text. The OCR result text is only required for the main text body, not for marginalia. If more text is submitted, make sure the respective regions are labelled as marginalia, for example.
Open source tools for exporting in the PAGE format are available from the PRImA Tools website.
Alternatively you can produce PAGE files using your own XML library, following the PAGE Schema.
Aletheia, a PAGE viewer and editor is also available for download so you can preview your results and check for validity of your produced XML files.
Filenames of submitted PAGE files should match the name of the original image.
Main text block detection / segmentation (Challenge 1)
- Polygons (enclosing the regions)
- Labels (classification into text-paragraph, text-marginalia, graphics / line drawing)
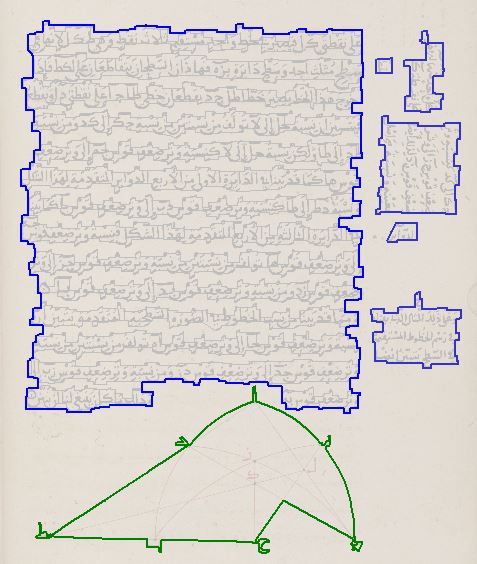
Text line detection / segmentation (Challenge 2)
- Polygons (enclosing each text line, child object of parent text region)

Text Recognition (Challenge 3)
- Text recognition results should be added to the corresponding text regions and/or text line objects as Unicode text content in the PAGE XML file.
- Text is only required for the main text body (not for the marginal handwritten text).
- OCR accuracy will be evaluated as a significant part of the overall score of a submitted method. Including OCR will therefore greatly improve the chance to win the competition.

Useful Hints
- Shape and size of polygons (region / text line outlines) do not matter as long as all relevant foreground content is included and anything else not belonging to the region is excluded (e.g. noise)
- Polygons should not overlap each other
- Not confident to tackle all three challenges? - You can use third-party methods / algorithms and perhaps improve the results (post-processing). Ask us for more information.
Example dataset
The example is available to participants after registration.
The following are examples of representative images from the variety of situations existing within the evaluation dataset.










Evaluation dataset
The evaluation dataset was made available on 4 May 2018.
Please email us at rasm2018@primaresearch.org to get access to the competition datasets (example set with ground truth and evaluation set images).